StackOverflow Retrieval with BigQuery and RAG
StackOverflow Retrieval with BigQuery and RAG is a solution designed to accelerate and automate the process of finding relevant answers from StackOverflow. Traditional methods involve manually browsing multiple questions, comparing content, and verifying answers. This process is tedious, time-consuming and delays producitvity.
The goal of this project is to streamline this experice using retrival-based AI approach with no latency. This project leverages Google BigQuery for public data access, embeddings for semantic encoding of questions, vector search to find similar questions, and Retrieval-Augmented Generation (RAG) to generate accurate, context-aware answers.
BigQuery approach
This project follows a Retrieval-Augmented Generation (RAG) pipeline:
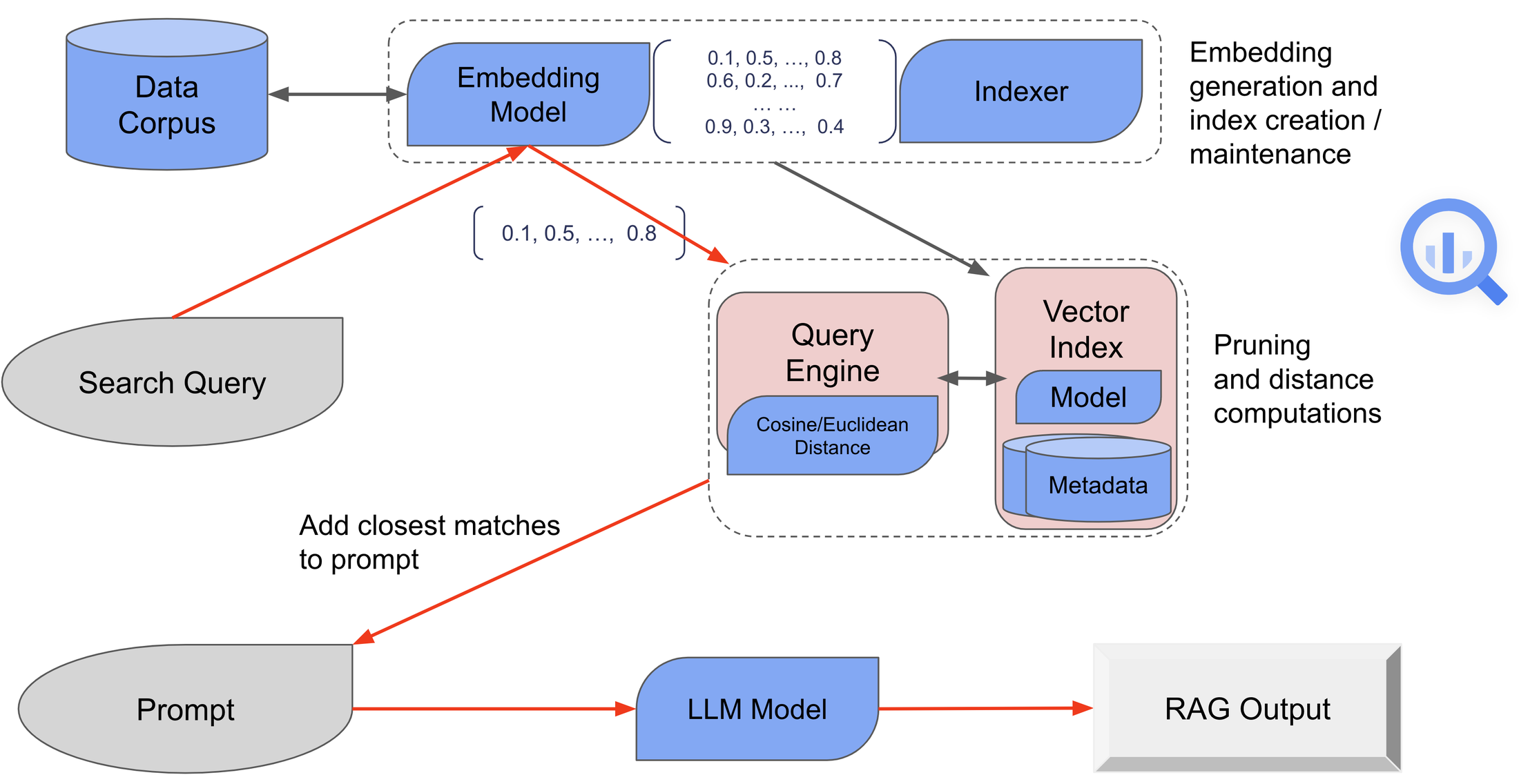 “image from google”
“image from google”
- Questions from StackOverflow are broken into chunk of smaller text segments. Each chunk is converted into a vector embedding using ML.GENERATE_EMBEDDING, capturing the semantic meaning of the text.
- The generated embeddings are stored in a vector index, optimized for fast similarity search using VECTOR_INDEX.
- When a user submits a question, the question content is also transformed into an embedding vector using the same embedding model.
- A vector similarity search is performed using VECTOR_SEARCH to compare the query embedding against the indexed embeddings.The system ranks the most relevant StackOverflow chunks based on similarity scores and top-matching results are selected to form a context window for the LLM language model.
- An LLM uses the retrieved context to generate a response that is directly grounded in real StackOverflow discussions.
Instruction to set up
The same as in instruction to set up for Sentiment Analysis of GitHub Comments project go to here
Steps
1. Create remote model
- My project name is
certain-voyager-470919-p7 - My dataset is
mydataset - Embedding model name is
embedding_model - LLM model name is
text_generation_model
CREATE OR REPLACE MODEL `certain-voyager-470919-p7.mydataset.embedding_model`
REMOTE WITH CONNECTION `projects/certain-voyager-470919-p7/locations/us/connections/vertexAI_connection`
OPTIONS (ENDPOINT = 'text-embedding-005');
CREATE OR REPLACE MODEL `certain-voyager-470919-p7.mydataset.text_generation_model`
REMOTE WITH CONNECTION `projects/certain-voyager-470919-p7/locations/us/connections/vertexAI_connection`
OPTIONS (ENDPOINT = 'gemini-2.0-flash-001');
1. Generate Vector Representations of Questions Using Embeddings
- create a table of Stack Overflow questions, including a column to store the embedding values for each question.
CREATE TABLE `certain-voyager-470919-p7.mydataset.embedding_questions` (
embedding ARRAY<FLOAT64>,
id INTEGER,
content STRING,
title STRING,
body STRING,
tags STRING,
accepted_answer_id INTEGER
);
- insert embedding values into the table using ML.GENERATE_EMBEDDING
- NOTE For this demo, generate embeddings only for questions related to the Python topic.
INSERT INTO `certain-voyager-470919-p7.mydataset.embedding_questions`
(id,embedding, content, title, body, tags, accepted_answer_id )
SELECT id,ml_generate_embedding_result AS embedding, content, title, body, tags, accepted_answer_id
FROM ML.GENERATE_EMBEDDING(
MODEL `certain-voyager-470919-p7.mydataset.embedding_model`,
(SELECT id, title, body, tags, accepted_answer_id , CONCAT(title, '\n', body, ' ', tags) AS content
FROM `bigquery-public-data.stackoverflow.posts_questions`
WHERE REGEXP_CONTAINS(tags, 'python') AND accepted_answer_id IS NOT NULL
),
STRUCT(TRUE AS flatten_json_output,
'RETRIEVAL_DOCUMENT' as task_type)
) AS e
WHERE e.id NOT IN (SELECT id FROM `certain-voyager-470919-p7.mydataset.embedding_questions` );
3. Use a vector index to enable efficient similarity search on the embedding column
CREATE OR REPLACE VECTOR INDEX `question_index`
ON `certain-voyager-470919-p7.mydataset.embedding_questions`(embedding)
OPTIONS(distance_type='COSINE', index_type='IVF');
4. Search for Similar Questions Using Vector Search + RAG
- Use VECTOR_SEARCH to retrievesimilar questions, join them with accepted answers from the BigQuery dataset.
- Create pairs of (Question, Answer) as context for generative model (LLM model)
DECLARE prompt, input_question STRING;
SET input_question = "what is different between list and tuple";
SET prompt = CONCAT("Propose a solution to the question '", input_question, "' using the question and answers from the database");
SELECT input_question, ml_generate_text_llm_result AS solution,
FROM ML.GENERATE_TEXT(
MODEL `certain-voyager-470919-p7.mydataset.text_generation_model`,
(
SELECT
CONCAT(prompt, STRING_AGG(FORMAT("question: %s, %s, answer: %s", base.title, base.body, a.body ))) AS prompt
FROM VECTOR_SEARCH(
TABLE `certain-voyager-470919-p7.mydataset.embedding_questions`,
'embedding',
(SELECT ml_generate_embedding_result,content
FROM ML.GENERATE_EMBEDDING(
MODEL `certain-voyager-470919-p7.mydataset.embedding_model`,
(SELECT input_question AS content ),
STRUCT()
)),
top_k => 5,
distance_type => 'COSINE',
options => '{"fraction_lists_to_search": 0.005}'
) AS q
JOIN `bigquery-public-data.stackoverflow.posts_answers` a
ON a.parent_id = q.base.id
),
STRUCT(600 AS max_output_tokens, TRUE AS flatten_json_output)
);
Example output
The solution I got from the question how to convert tuple to list is:
def tuple_to_list(input_tuple):
"""
Converts a tuple to a list.
Args:
input_tuple: The tuple to convert.
Returns:
A list containing the elements of the tuple.
"""
return list(input_tuple)